
Why, when, who, and how – 10 things you always wanted to know about data cataloguing but were too afraid to ask
Imagine you are stepping into a well-organised library — one where each book has a detailed card describing what’s inside, who wrote it, and why it matters. That is essentially what a data catalogue does for your organisation’s data. On the contrary, in today’s data-driven landscape you may have noticed data lying scattered across various systems, formats, and repositories. In this blog post, we unravel the mysteries of data cataloguing in a way that’s both informative and approachable. Covering the why, when, who, and how, we explore the 10 essential things you always wanted to know about data cataloguing but were perhaps too hesitant to ask.
1. What is a data catalogue?
A data catalogue is a structured record of datasets aimed at supporting data discovery. Unlike a data inventory, which only provides a limited record of datasets for internal tracking purposes, or a data registry, which is primarily focused on data governance and data management, a data catalogue aims to help users discover, understand, and effectively use the available data resources. Benefits of using a data catalogue include enhanced data quality, increased productivity for data users, and better decision-making based on a clear understanding of available data assets.
While a data catalogue gives a structured overview of data assets, however, it is important to note that it does not necessarily give access to the data. The catalogue is simply an overview of the data asset through metadata, namely information about its content, context, and relevance.
Simply put, a data catalogue could be compared with a product or library catalogue. It is mostly used by researchers and analysts, however, the data catalogue can also be used a powerful tool that acts as a bridge between data providers and consumers.
What does a catalogue include?
A data catalogue includes metadata and distribution information. In principle, a data catalogue is very similar to a product catalogue. While you have access to the full product catalogue, it does not mean that you have access to (or own) all the products within.
In the catalogue, you can see
- Basic metadata: the main features such as the product title, price and colour
- Extended metadata: detailed descriptions, such as care instructions and dimensions
- Distribution information: information on availability and accessibility, such as where you can buy the product.
- Related assets: links to similar datasets, such as related products, in the case of a product catalogue.
Similar to a product catalogue, a data catalogue supports you to find the data that you need and where and how you can access it.
2. Do I need a data catalogue?
As a researcher or analyst, you might think that you do not need a catalogue, you know your data and how to access it. However, even if you know where your data is, your organisation or future collaborator may not know. It is important that you clarify where data is, so that the value of the data can increase. Structured and organised data has a much higher value than unstructured and unorganised data.
A data catalogue is important to help you keep track of your data – your most important asset. Like with physical assets, it is important for your organisation to know amongst other:
- Where is the data located?
- Who owns the data?
- When was the data created and how?
- Who is allowed to access the data? What are the access limitations?
3. How to do data cataloguing?
Data cataloguing is based on three main ingredients:
- A metadata model – what metadata do you need to collect?
- A cataloguing infrastructure – where do you collect the metadata?
- A cataloguing process – how and when do you collect metadata?
After you have identified your three ingredients, we dive into the three steps of data cataloguing:
3.1. Start with the purpose – why do you want to make a catalogue?
Make sure you need a catalogue and not just an inventory of your data. By outlining the goal and the audience of your data catalogue you can determine if you need a data catalogue.
If your goal is to support analysts, researchers and business users to discover and leverage your organisation’s data assets to their fullest extent for data-driven decision-making and increased value generation, you may need a data catalogue. If on the contrary, you only want to maintain an overview of your data assets to support data stewards and managers in their work, and encourage improved transparency around data security and data governance, a data inventory may be enough.
3.2. Understand that data cataloguing is an iterative process
Data cataloguing is a continuous process, involving numerous stakeholders. When you have decided that you need a data catalogue and start building it, you should:
- Identify basic metadata needs
- Build an initial data inventory
- Define & implement infrastructure requirements
- Set up cataloguing processes
- Enable extended metadata based on emerging business needs
3.3. Make sure that you have buy-in from all data stakeholders
Last but not least, you need to make sure that the people around you understand why you want the data catalogue. Data managers and decision makers may have different views and needs. It is important that you align the needs of the different stakeholders, so that the data catalogue can benefit all.
4. What is a dataset?
As defined by DCAT v3 , a dataset is “A collection of data, published or curated by a single agent, and available for access or download in one or more representations”.
The term Single agent is a key element in the defining of dataset. This means that one dataset is always limited to a certain moment in time and a certain purpose. To put it in layman’s terms, a dataset is a collection of data, collected for a specific topic and purpose, and within a defined timeframe. For example, a dataset can be the collection of temperature data during the year 2023 in Luxembourg.
A dataset can also include other datasets. When datasets are related to each other in a hierarchy it is called datasets of datasets. For example, in your dataset of temperature data during the year 2023 in Luxembourg, you have datasets of temperature data during the year 2023 from different cities in Luxembourg. Your 2023 temperature dataset for Luxembourg may, in turn, be integrated into a larger dataset of temperature data for all of Europe for 2023, or for Luxembourg for multiple years.
5. When should I register metadata?
First of all, let’s define metadata. Metadata is the information about a dataset’s content, context, and relevance.
Metadata needs to support the data lifecycle and you gather metadata throughout the data journey. It is important that you register basic information as early as possible, update the information regularly, create links to other related datasets as they emerge, and capture the information about data processing in a structured format.
Important to note – metadata collection processes are data governance processes! Metadata collection should be at the core of your data governance processes. Through proper metadata handling you will master your data governance.
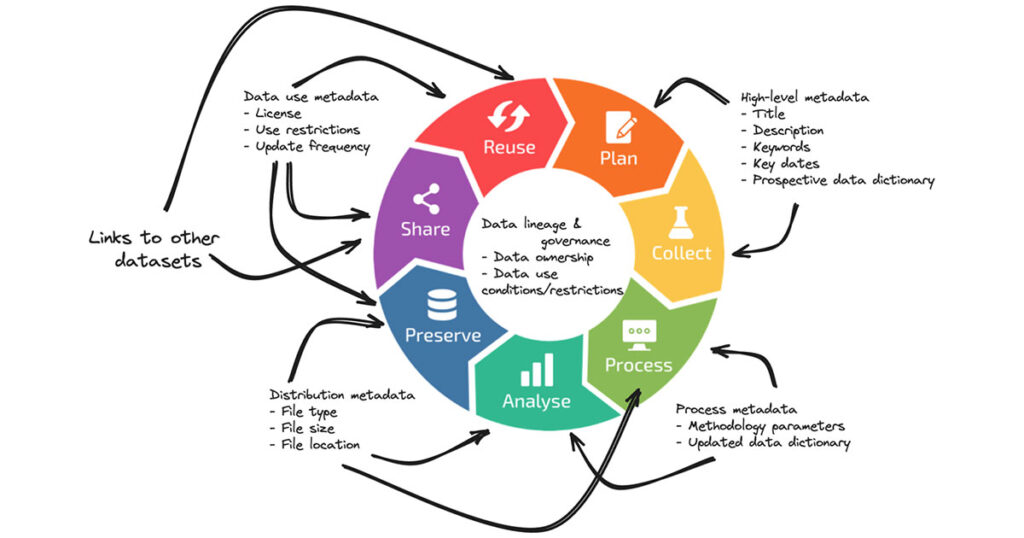
Source: Created by LNDS by reusing the data lifecycle of the ELIXIR Europe RDM Kit
6. To update or to create a new dataset – that is the question!
The choice to update or create a new dataset depends from data type to another. The rule-of-thumb is to define sensible cut-offs and avoid data files becoming too big or numerous to usefully process. How do you then know where to draw the line?
As a golden rule you can think to:
Update your dataset when the you add additional data to a same sample, within the same time period. For example, re-analysing biological samples for the presence/absence of additional metabolites.
Create new data set: when you have different samples from different domains or in different time and/or place. For example, water samples from different locations at different times of the year.
7. Who is responsible for metadata?
A common misconception is that everyone involved with metadata thinks that the responsibility is on the other party. In fact, there is no one party more or less responsible for the metadata – it is everyone’s responsibility! Data experts, data managers, researchers and analysts all have a different responsibility in building up complete metadata. Everyone should contribute to the metadata with their part to build the full picture. Without one part, an important part can go missing.
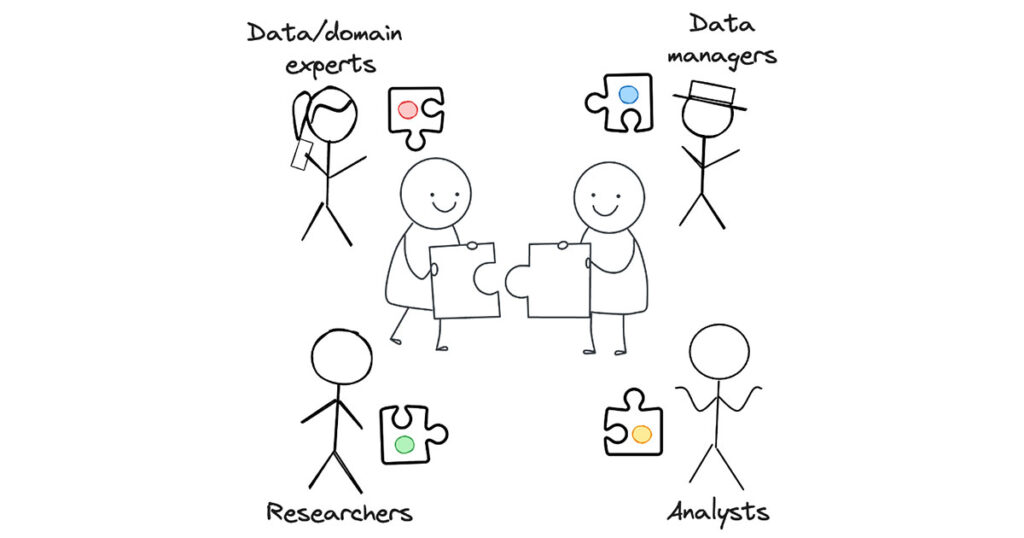
Source: Created by LNDS using Excalidraw.
8. Open metadata vs. restricted data – what is the difference?
A commonly heard misconception is “I can’t register my dataset because it contains sensitive data!”.
Metadata only describes what the dataset covers, but it does not reveal any information of the data itself. By publishing the description of the data, you are not revealing the sensitive data itself. All sensitive and personal data is behind an access request and strictly accessible only by authorised parties.
As a summary, open metadata is simply “data about data”, while restricted data is the actual data behind and access barrier. We will cover this topic in further detail in an upcoming blog.
9. Catalogue interoperability – make sure metadata can be indexed by another catalogue
Catalogues often cross-index each other or are indexed by larger catalogues such as thematic-, national- and even international catalogues. Therefore it is important to make sure that the metadata of your catalogue can be indexed by other catalogues .
In order to enable indexing, it is important that you use the same structure in your metadata. This can be done by using:
- widely accepted metadata models (generic, e.g. DCAT or domain specific, e.g. DATS)
- use standardised terminology
- expose metadata through APIs or harvestable page markup
10. Why a catalogue is not just a nice to have, but actually necessary?
Data reuse starts with discoverability. Having a structured way of accessing data is an essential base for enabling secondary use of data. There are also many regulations and legislations for secondary use of data, setting requirements for data cataloguing. As an example, in Luxembourg as a EU country, we are bound by EU legislation such as the Data Governance Act and European Health Data Spaces (EHDS) with Health Data Acess Bodies (HDAB).
The Luxembourg National Data Catalogue
To map the (public) data landscape in Luxembourg, LNDS is currently developing the Luxembourg National Data Catalogue. Our goal is to create a gateway to all sensitive data from public administrations and related entities available for secondary use in Luxembourg. The work is in progress to create a systematic catalogue of the data landscape in Luxembourg.
It is important to note, that it is not a project of its own, but aims to cross-index and exchange with other data catalogues, such as the Open Data platforms.
The scope of the Luxembourg National Data Catalogue is broad and aims to include all sectors, including, but not limited to health, environment, transport, and finance. As any data catalogue, the National Data Catalogue will only show the metadata. Data access and restrictions are defined by the data provider and depends from provider to provider and the legal basis for accessing the data. All access requests will be assessed to the legal basis of the data
Make your data discoverable – Contribute with metadata to the Luxembourg National Data Catalogue
Would you like to enable more value of your data? We appeal to make data discoverable. By making data discoverable you can create more value from your data!
By adding your data to the national data catalogue :
- the metadata of your data will be visible – i.e. other researchers can know that your data exists
- you remain the sole owner and controller of your data. i.e. no direct links to the data
- we will facilitate the access request if we are approached by an entity who would be interested in accessing (a part of) your data
Please note that you will always remain the sole owner of the data and the access request will be assessed based on the legal basis. In other words, the data can only be used for the legal basis for which it was collected.
How to submit metadata to the catalogue ?
If you want to be visible in the national data catalogue, please send us an email to service@lnds.lu and our team of experts will help you from there.
Support for Data Cataloguing
We hope that this blog post has answered you questions about data cataloguing. LNDS also provides support for data cataloguing in the form of our Data Cataloguing service.
Please reach out to us if you have further questions about data cataloguing or how to be part of the Luxembourg National Data Catalogue, Our team will be glad to support you.
This blog post is based on the thematic talk “Why, when, who, and how – 10 things you always wanted to know about data cataloguing but were too afraid to ask” by our Principal Data Analyst Danielle Welter, on 16th February, organised by the Data Management Community. The Data Management Community organises regular workshops and thematic talks for their community members. Learn more about the community activities and how to become a member.